
Nhận dạng giọng nói được sử dụng khá phổ biến trong nhà thông minh, công nghệ xe tự hành,... Hãy cùng tìm hiểu kỹ hơn về công nghệ nhận diện giọng nói trong bài viết này.
 Ngày nay, giọng nói có khả năng điều khiển nhiều thiết bị thông minh nhờ vào công nghệ nhận dạng giọng nói. Công nghệ này đã bắt đầu được nghiên cứu từ những năm 1936. Tuy nhiên, nó mới chỉ xuất hiện trên các thiết bị điện toán cá nhân khoảng gần 30 năm trở lại đây.
Ngày nay, giọng nói có khả năng điều khiển nhiều thiết bị thông minh nhờ vào công nghệ nhận dạng giọng nói. Công nghệ này đã bắt đầu được nghiên cứu từ những năm 1936. Tuy nhiên, nó mới chỉ xuất hiện trên các thiết bị điện toán cá nhân khoảng gần 30 năm trở lại đây.
Với sự phát triển không ngừng của kỷ nguyên số, nhận dạng giọng nói cũng không ngừng được nâng cấp để hỗ trợ cuộc sống của con người hiện đại hơn.
1. Nhận dạng giọng nói là gì?
Nhận dạng giọng nói (Speech recognition) là khả năng máy móc, chương trình máy tính xác định, “hiểu” ngôn ngữ của con người và xử lý lời nói thành văn bản.
Phần mềm nhận dạng giọng nói trước đây có vốn từ vựng hạn chế, chỉ có thể xác định được các từ và cụm từ khi được nói rõ ràng. Sau này, những phần mềm phức tạp hơn cho phép xử lý giọng nói tự nhiên với nhiều chất giọng và ngôn ngữ khác nhau.
Nhận dạng giọng nói sử dụng nhiều trong nghiên cứu khoa học máy tính, ngôn ngữ học và kỹ thuật máy tính. Công nghệ này bao gồm 2 khái niệm cần phân biệt: Đó là speech recognition và voice recognition.
Speech recognition được sử dụng để xác định từ ngữ trong lời nói của con người và chuyển chúng sang ngôn ngữ máy tính.
Voice recognition là công nghệ sinh trắc học nhằm xác định giọng nói của một cá nhân nào đó.
Trong nội dung dưới đây, Elcom phân tích chuyên sâu về khái niệm “Speech recognition”.
2. Nhận dạng giọng nói hoạt động như thế nào?
Hệ thống nhận dạng giọng nói sử dụng thuật toán máy tính để xử lý và giải thích các từ được nói ra và chuyển chúng thành văn bản. Nhiều chương trình phần mềm có thể chuyển âm thanh micrô ghi lại thành ngôn ngữ viết mà máy tính và con người có thể hiểu được, theo bốn bước sau:
Phân tích âm thanh đầu vào;
Chia âm thanh thành nhiều phần;
Số hóa âm thanh thành định dạng máy tính đọc hiểu được;
Sử dụng thuật toán để chuyển âm thanh thành văn bản và trả lại đầu ra cho người dùng.
Phần mềm nhận dạng giọng nói phải thích ứng với tính chất rất đa dạng và hiểu được ngữ cảnh của lời nói con người. Các thuật toán được đào tạo về nhiều mẫu giọng nói, phong cách nói, ngôn ngữ, phương ngữ, chất giọng và cụm từ khác nhau, đồng thời phân tách giọng nói khỏi những tạp âm khác.
Để đáp ứng các yêu cầu này, hệ thống nhận dạng giọng nói sử dụng hai loại mô hình:
Mô hình âm thanh (Acoustic models): Chúng thể hiện mối quan hệ giữa đơn vị ngôn ngữ của lời nói và tín hiệu âm thanh.
Mô hình ngôn ngữ (Language models): Âm thanh được khớp với chuỗi từ để phân biệt từ đồng âm khác nghĩa.
3. Tính năng của hệ thống nhận dạng giọng nói
Với chương trình nhận dạng giọng nói tốt, người dùng có thể tùy chỉnh theo nhu cầu của họ. Các tính năng cho phép điều này bao gồm:
Trọng số ngôn ngữ: Tính năng này yêu cầu thuật toán chú ý đặc biệt đến một số từ nhất định, chẳng hạn như những từ được nói thường xuyên hoặc dành riêng cho một chủ đề cụ thể. Ví dụ: Phần mềm được đào tạo để lắng nghe tài liệu tham khảo về sản phẩm xác định.
Đào tạo âm thanh: Phần mềm điều chỉnh tiếng ồn xung quanh làm ảnh hưởng âm thanh nói. Chương trình này phân biệt phong cách nói, tốc độ và âm lượng trong bối cảnh ồn ào.
Gắn nhãn người nói: Khả năng này cho phép chương trình gắn nhãn cho từng người tham gia và xác định âm thanh cụ thể của họ cho cuộc trò chuyện.
Lọc lời nói thô tục: Phần mềm lọc ra những từ và ngôn ngữ không mong muốn.

Các thiết bị nhận dạng giọng nói phân biệt giọng nói của từng đối tượng - Ảnh: Internet
4. Ứng dụng nhận diện giọng nói trong thực tiễn
Hệ thống nhận dạng giọng nói hiện nay được ứng dụng phổ biến. Ví dụ:
Thiết bị di động: Điện thoại thông minh sử dụng lệnh thoại để định tuyến cuộc gọi, xử lý giọng nói thành văn bản, quay số và tìm kiếm bằng giọng nói. Người dùng có thể trả lời tin nhắn mà không cần nhìn hay chạm vào thiết bị của họ.
Ví dụ, trên iPhone của Apple, tính năng nhận dạng giọng nói hỗ trợ bàn phím và trợ lý ảo Siri. Nhận dạng giọng nói cũng được tìm thấy trên những ứng dụng xử lý văn bản hiện đại như Microsoft Word, cho phép người dùng đọc chính tả các từ để chuyển thành văn bản.
Giáo dục: Phần mềm nhận dạng giọng nói được sử dụng trong giảng dạy ngôn ngữ. Phần mềm nghe lời nói của người dùng và cung cấp trợ giúp về cách phát âm.
Bán hàng: Công nghệ nhận dạng giọng nói giúp trung tâm cuộc gọi ghi lại hàng nghìn cuộc trao đổi giữa khách hàng và nhân viên tổng đài để xác định những vấn đề thường gặp.
Các chatbot trí tuệ nhân tạo (AI - Artificial Intelligence) có khả năng trò chuyện với khách hàng thông qua giao diện nhắn tin, trả lời các truy vấn phổ biến và giải quyết những yêu cầu cơ bản mà không cần đợi nhân viên con người có mặt tại trung tâm cuộc gọi.
Ứng dụng chăm sóc sức khỏe: Bác sĩ có thể sử dụng phần mềm nhận dạng giọng nói để ghi chú theo thời gian thực vào hồ sơ chăm sóc sức khỏe.
Nhận dạng cảm xúc: Công nghệ này cho phép phân tích một số đặc điểm giọng nói nhất định để xác định cảm xúc của người nói. Nó hỗ trợ người bán hàng nhận biết được cảm xúc của khách hàng khi tiếp nhận sản phẩm, dịch vụ để có cách tiếp cận phù hợp.
Giao tiếp rảnh tay: Tài xế sử dụng tính năng điều khiển bằng giọng nói để liên lạc rảnh tay, điều khiển điện thoại, radio và hệ thống định vị toàn cầu (GPS - Global Positioning System).
5. Thuật toán sử dụng trong nhận dạng giọng nói
Những thay đổi thất thường trong lời nói của con người gây khó khăn cho sự phát triển công nghệ nhận diện giọng nói. Đây được coi là một trong những lĩnh vực phức tạp nhất của khoa học máy tính - liên quan đến ngôn ngữ học, toán học và thống kê.
Công nghệ nhận dạng giọng nói được đánh giá dựa trên tỷ lệ chính xác của nó, tức là tỷ lệ lỗi từ (WER - Word error rate) và tốc độ. Một số yếu tố ảnh hưởng đến tỷ lệ lỗi từ bao gồm: Cách phát âm, trọng âm, cao độ, âm lượng và tiếng ồn xung quanh. Mục tiêu của các hệ thống nhận dạng giọng nói là giảm thiểu tối đa tỉ lệ lỗi từ.
Những thuật toán và kỹ thuật tính toán khác nhau được sử dụng để nhận dạng và chuyển đổi giọng nói thành văn bản, cải thiện độ chính xác của quá trình phiên âm. Dưới đây là giải thích ngắn gọn về một số phương pháp được sử dụng phổ biến nhất:
Xử lý ngôn ngữ tự nhiên (NLP)
Mặc dù NLP - Natural Language Processing không nhất thiết phải được sử dụng trong nhận dạng giọng nói, nhưng đây là lĩnh vực trí tuệ nhân tạo tập trung vào sự tương tác giữa con người với máy móc thông qua ngôn ngữ, lời nói và văn bản.
Nhiều thiết bị di động kết hợp nhận dạng giọng nói để tiến hành tìm kiếm hoặc ra lệnh thực hiện các tác vụ ở chế độ rảnh tay. Ví dụ: Siri trên điện thoại iPhone của Apple.
Mô hình Markov ẩn (HMM - Hidden markov models)
Mô hình Markov ẩn (tiếng Anh là Hidden Markov Model - HMM) là mô hình thống kê, trong đó hệ thống được mô hình hóa xem như một quá trình Markov với các tham số không biết trước. Nhiệm vụ là xác định tham số ẩn từ những tham số quan sát được.
Tham số được rút ra từ mô hình có thể sử dụng để thực hiện quá trình phân tích kế tiếp, ví dụ ứng dụng cho nhận dạng mẫu. Mô hình này quy định rằng xác suất của một trạng thái nhất định phụ thuộc vào trạng thái hiện tại chứ không phải các trạng thái trước đó.
Mô hình markov ẩn cho phép kết hợp những sự kiện ẩn vào mô hình xác suất, chẳng hạn như gán nhãn từ loại. Chúng được sử dụng làm mô hình trình tự trong nhận dạng giọng nói, gán nhãn cho từng đơn vị: Từ, âm tiết, câu,... Các nhãn này tạo ra một ánh xạ với đầu vào được cung cấp, cho phép nó xác định chuỗi nhãn thích hợp nhất.
N-gram
Đây là loại mô hình ngôn ngữ (LM - Language Model) đơn giản nhất, gán xác suất cho các câu hoặc cụm từ. Một N-gram là chuỗi N-từ. Ngữ pháp và xác suất của các chuỗi từ nhất định được sử dụng để cải thiện khả năng nhận dạng và tăng độ chính xác.
Mạng thần kinh nhân tạo
Được tận dụng chủ yếu cho các thuật toán học sâu, mạng nơ-ron thần kinh nhân tạo xử lý dữ liệu huấn luyện bằng cách bắt chước khả năng kết nối của bộ não người thông qua các lớp nút. Mỗi nút được tạo thành từ đầu vào, trọng số, độ lệch (hoặc ngưỡng) và đầu ra. Nếu giá trị đầu ra đó vượt quá một ngưỡng nhất định, nó sẽ kích hoạt nút, truyền dữ liệu đến lớp tiếp theo trong mạng.
Mạng nơ-ron nhân tạo học chức năng ánh xạ này thông qua học tập có giám sát, điều chỉnh dựa trên hàm mất mát (loss function) thông qua quá trình giảm độ dốc.
Mạng lưới thần kinh có xu hướng chính xác hơn và có thể chấp nhận nhiều dữ liệu hơn. Tuy nhiên, điều này lại làm giảm hiệu quả hoạt động vì chúng sẽ đào tạo chậm hơn so với mô hình ngôn ngữ truyền thống.
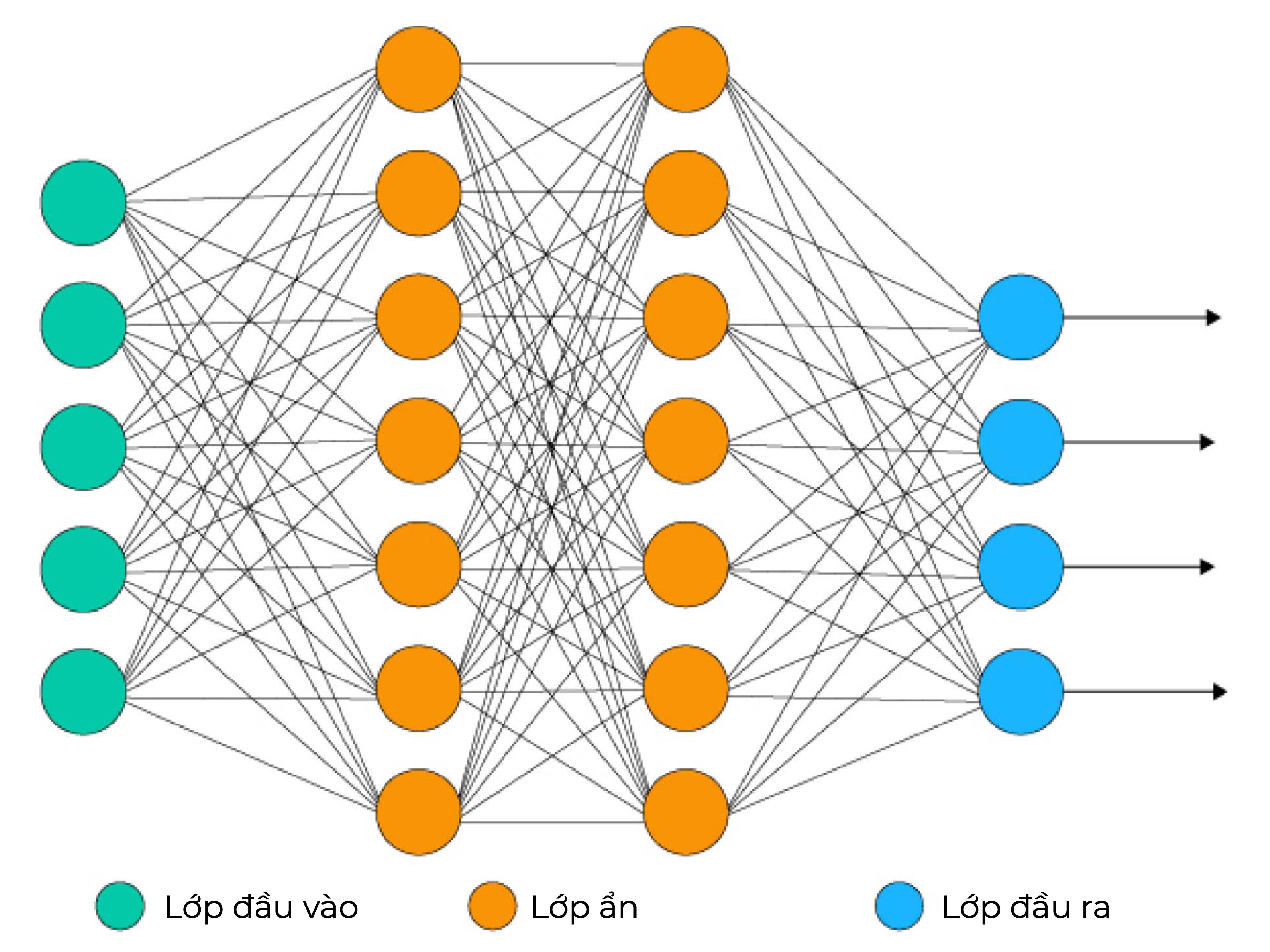
Cấu trúc của mạng nơ-ron đơn giản - Ảnh: Internet
Gắn nhãn người nói (SD - Speaker Diarization)
Thuật toán gán nhãn người nói là quá trình xác định và gán phân đoạn lời nói cho người nói tương ứng. Điều này giúp chương trình phân biệt tốt hơn các cá nhân trong cuộc trò chuyện.
Thuật toán SD thường xuyên được áp dụng tại những tổng đài phân biệt khách hàng và nhân viên tổng đài.
Với nhiều ứng dụng phổ biến trong thực tiễn, các thiết bị nhận diện giọng nói đóng vai trò quan trọng đối với đời sống hiện đại. Do đó, công nghệ nhận dạng giọng nói nói chung được đánh giá là một trong những xu hướng có khả năng phát triển tốt trong tương lai.
Nguồn tham khảo: https://www.ibm.com/topics/speech-recognition
![[ELCOM ITS] Inside ELCOM ITS: Cách các hệ thống giao thông thông minh được tạo ra](https://elcom.com.vn/storage/uploads/images/T9bk59vjsZOeOLnZd6MTL9aIlD8hjfdts1x0BhFU.png)
![[ELCOM ITS] Toàn cảnh bức tranh giao thông đô thị Việt Nam](https://elcom.com.vn/storage/uploads/images/r39s7ufmcggta29Taw5iGprfb4tMLb2beRmGsSBg.png)
![[ELCOM ITS] Lịch sử ITS Việt Nam: Hành trình thông minh hóa giao thông quốc gia](https://elcom.com.vn/storage/uploads/images/OPLZ1SxPQYi9Dzhztc48h0RHTeo4biTvTEhzBLeW.png)

